Problem
The operation’s LPs were on shared hosting. Single region. No versioning. No rollback when a deploy misbehaved.
The downstream effect was operational fear. The team had stopped deploying. They wouldn’t ship a creative change at 2pm because they couldn’t be sure it wouldn’t break something. Compliance updates required manual edits across hundreds of pages, which made compliance updates rare. The infrastructure was setting the pace of the operation, and the pace was slow.
The deeper problem: their best campaigns were on tier-one mobile traffic. The infrastructure they’d built was a constant TTFB tax on every visitor. The CR ceiling on the operation was being set by their hosting, not by their offers. Nobody had quantified this. It just felt like the team was working hard and the numbers weren’t moving.
System
We replatformed every active LP onto an edge-delivered runtime. Twelve regions. Versioned releases. One-command rollback. Compliance routing built into the delivery layer, so jurisdiction-specific variants serve from the same URL without redirects.
The specific architectural choices are the part we don’t lay out in public. The choices we made for this operation were specific to their team, their stack, and their willingness to operate the layer themselves after we left. A different operation with a different shape would get a different architecture.
What’s portable is the principle. Infrastructure that respects what the team is trying to do — deploy often, deploy safely, roll back quickly, serve fast — is itself a leverage point. Most teams have never asked whether their hosting is helping or hurting them. The answer, for serious operations, is almost always “hurting.”
Outcome
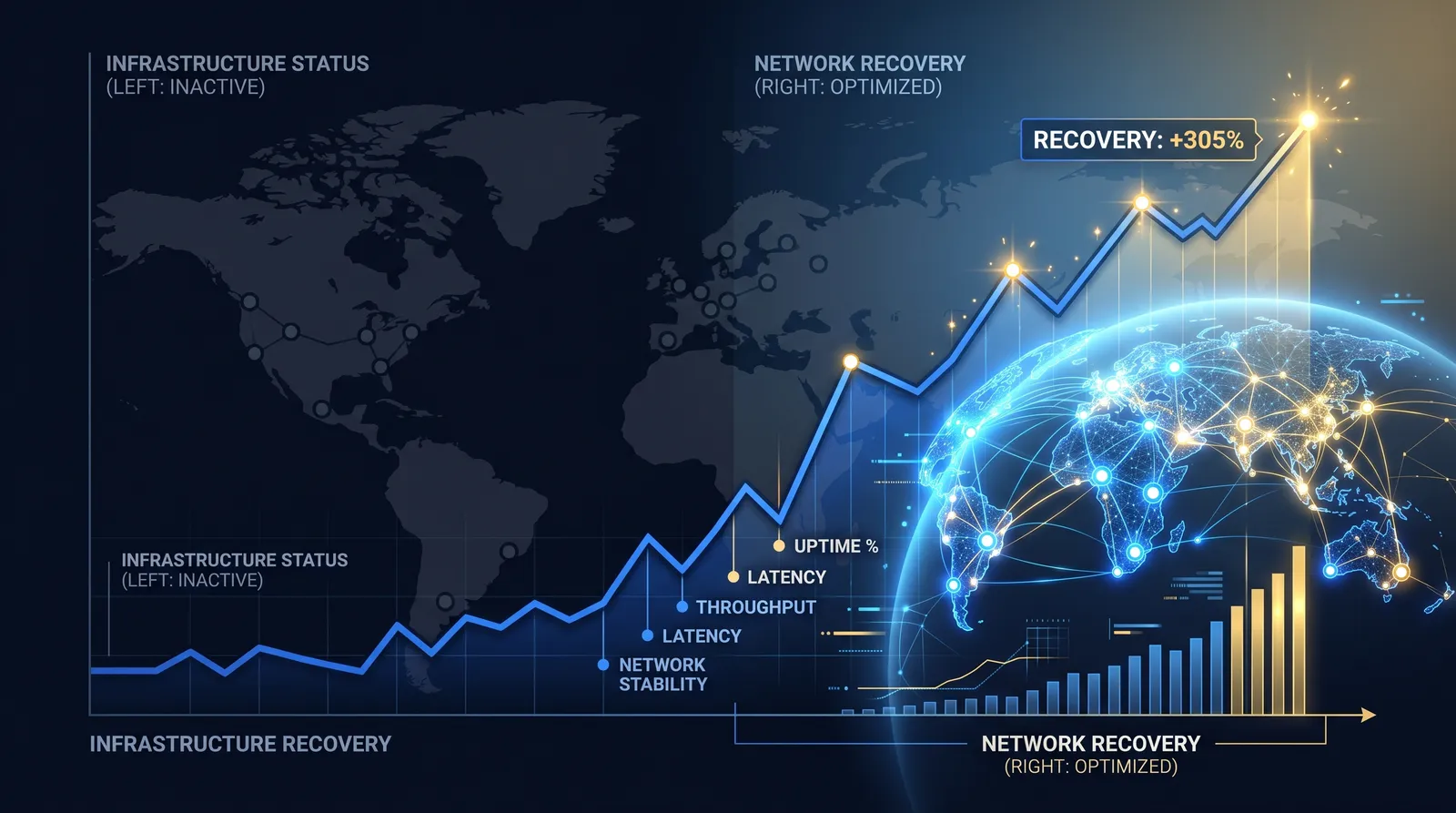
Net ROI on the operation recovered by more than three hundred percent over ninety days. The recovery had three sources.
The largest was TTFB. The new stack served pages an order of magnitude faster on mobile. CR moved across every campaign, not just the ones we touched. That was the immediate effect.
The second was deploy velocity. Going from five fearful deploys a week to twenty routine ones changed what the team could test. They started iterating on creative-and-LP combinations the same week they thought of them, instead of two weeks later. The compounding showed up in week six.
The third was compliance speed. Verticals the team had been avoiding because of compliance overhead became operable. New offers got tested faster. The team’s catalog of what they could profitably run grew.
The infrastructure didn’t make the team better at media buying. It removed the constraints that had been making the team look slower than they actually were. That’s usually the right shape for an infrastructure intervention. If the operation gets dramatically better immediately after you replace a layer, you didn’t have a strategy problem. You had an infrastructure problem.
Get case study breakdowns like this
One email when we publish. No spam, unsubscribe anytime. By subscribing you agree to our Privacy Policy.